再刷洛谷试炼场,发现试炼场已经无了。开始以为找不到了,知乎上看到站长的回复才知道真的无了。我是从这个人整理的版本里刷的:https://www.luogu.com.cn/paste/66uuuvdr 用 Go 大概刷了 10 道题之后,放弃洛谷。原因是洛谷几乎都是 C++选手。
继续用 Go 在 LeetCode 刷题。遇到什么写什么吧。纯纯的笔记。非专题性内容。
输入输出
才发现用 go 刷题连输入输出都不会
print在golang中 是属于输出到标准错误流中并打印,官方不建议写程序时候用它。可以debug时候用fmt.print在golang中 是属于标准输出流,一般使用它来进行屏幕输出.
处理字符串
1 | func replaceSpace(s string) string { |
- 03. 数组中重复的数字 交换法
快慢指针
快指针在前面探路,慢指针满足条件再走。
eg. 删除数组、链表中的重复元素
283 删除0
我的方法:遇到 非0 就填充,最后把没填充的再填充 0;
更优:遇到非 0,就交换。这样 0 会被不停地往后换。
前缀和
快速算区间和
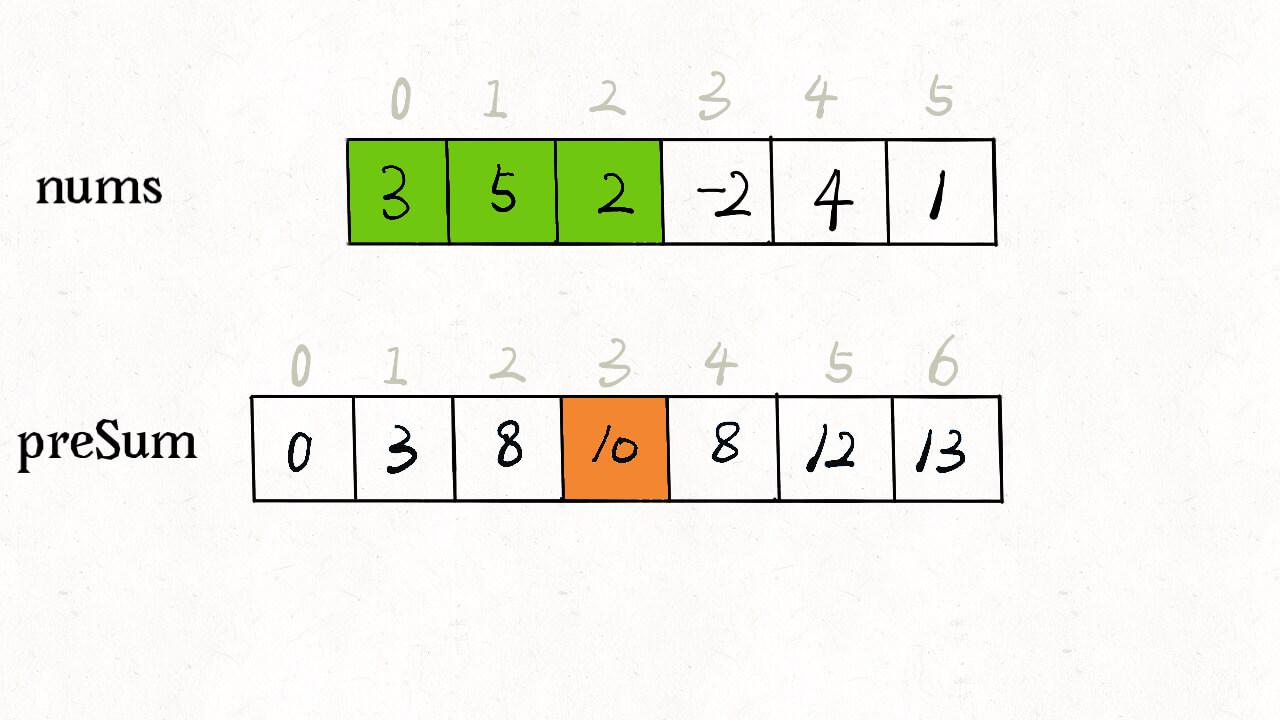
Sum(nums[i]–nums[j]) = preSum[j+1]-preSum[i]
二维数组前缀和 https://leetcode-cn.com/problems/range-sum-query-2d-immutable/submissions/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20func Constructor(matrix [][]int) NumMatrix {
l := len(matrix)+1
preSum := make([][]int, l)
for i:=0;i<len(preSum);i++{
preSum[i] = make([]int, l)
for j:=0;j<len(preSum[i]);j++ {
if i == 0 || j == 0{
preSum[i][j] = 0
continue
}
//注意最后这个 -
preSum[i][j] = preSum[i-1][j] + preSum[i][j-1]+ matrix[i-1][j-1] - preSum[i-1][j-1]
//println(i,j,":",preSum[i-1][j],preSum[i][j-1],matrix[i-1][j-1],"-",preSum[i-1][j-1],"=",preSum[i][j])
}
}
return NumMatrix{
Matrix: matrix,
PreSum: preSum,
}
}1
2
3
4
5
6
7
8
9
10func (this *NumMatrix) SumRegion(row1 int, col1 int, row2 int, col2 int) int {
//println(this.PreSum[row2+1][col2+1] , this.PreSum[row1][col2+1] , this.PreSum[row2][col1] , this.PreSum[row1][col1])
// row1和 col1 都是不+1,row2 和 col2 都+1
return this.PreSum[row2+1][col2+1] - this.PreSum[row1][col2+1] -
this.PreSum[row2+1][col1] + this.PreSum[row1][col1]
}
差分数组
☆☆☆频繁对区间进行删减的情况☆☆☆
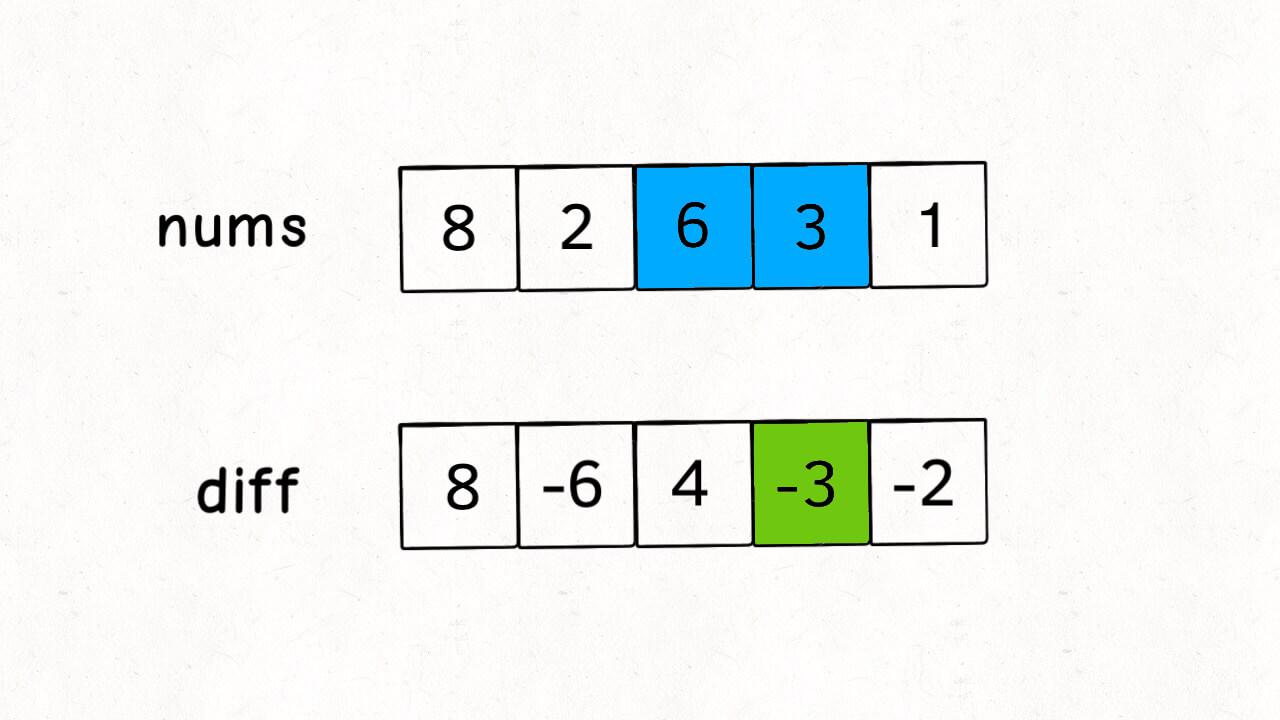
nums[i] = diff[i] + nums[i-1]nums[i..j]都 +3 等于diff[i]+=3 , diff[j+1]-=3
但是注意, nums 更新最后一个数字时,diff[j+1]会越界,所以不用再更新
- 遍历 diff 数组即可还原 nums 数组。
回文
二分
直接二分搜索
1 | // 关键两点 |
二分一定记得不要重复使用已经判断过的边界m,下次循环一定要m+1、m-1
二分变形
通过二分查找试出最佳值
- 取整技巧:
(x + n -1)/n == int(ceil(x/n))
滑动窗口
我写的滑动窗口有思想问题
比如找无重复的最长子串,滑动[i..j],我是 外循环 j++,j 不停地往后,发现重复则把 i 更新到出现过的位置。清空 map 重新记录一次。
标准的思想:[i..j],外循环是 i ++, 每次以 i 为开头,内循环 j ++ 尝试找出 以 i 开头最长的。
每次外循环 i++时 删除 map 里的前一个元素 delete(m, s[i-1])
container
go 里没有栈。但container 包里的 list、heap和 ring 也勉强够用。
只是用起来稍微有点绕(特别是不能定义容器的元素类型,遇到返回 Value 的题还要断言一下)
下面遇到某个 container 就整理一下
list
链表就是一个有 prev 和 next 指针的数组了。它维护两个 type,( 注意,这里不是 interface)
1 | type Element struct { |
基本使用是先创建 list,然后往 list 中插入值,list 就内部创建一个 Element,并内部设置好 Element 的 next,prev 等。具体可以看下例子:
1 | // This example demonstrates an integer heap built using the heap interface. |
list 对应的方法有:
1 | type Element |
下面演示一个模拟栈的 pop
1 | x,_ := this.stack.Remove(this.stack.Back()).(int) |
使用注意
1 | this.Lst.MoveToFront(ele) |
heap
注意,heap 只是保证顶部是最小。不会保证按顺序输出是最小
实现 interface 时只需要注意 Pop() 方法的写法 ,比如最简单的 []int 类型:
1
2
3
4
5
6
7func (p *PriorityQ) Pop() interface{} {
n := len(*p)
old := *p
x := old[n-1]
*p = old[:n-1]
return x
}
单调栈、单调队列
「单调栈」 Next Great Number 类问题
「单调队列」滑动窗口相关的问题
二叉树
114.二叉树展开为链表(中等)
这里有一点需要注意就是递归的去处理 root 的左右子树 x 和 y 时,
1 | root.Left = nil #左子树指向 nil |
root.Left = nil
二叉搜索树的变更
三种情况
- 叶子节点,没啥牵挂
- 一个孩子,方便
- 俩孩子,不好管理
BFS
LeetCode752,我的 BFS 为啥超时呢。
首先,queue队列用数组就可以实现,没必要用container 包里的 list(但这个影响也不大)
比较重要的一点,慢的 BFS 是用了层序遍历思想,每次把同级别的符合条件的都入队,
其实这样也可以实现。但是这会导致什么情况:
入队的数量呈指数级别上升。比如这次入队 2 个,下次入队就这 2 个的下一种情况4 个,然后就是 8、16
最终就会发现队列超级长
而只需要每次都只取队列里的头部 1 个!1 个!1 个元素!,这样就大大降低了队列的长度。(只是循环次数会增加)
但是有一说一。我只分析出这两种方案这里会不同。还是没法分析出为啥那个就可以秒出结果。
回溯
- 全排列
go 的这个切片这一块,回滚是真的麻烦。
比如你先把第 i 个元素给 remove,再接 i 回来就得这样:
1 | x:=nums[i] //存下 i |
没办法,要么就重新开辟一个切片做深拷贝:
1 | # 深拷贝笨方法 |
这里注意一个切片append的细节:
1 | x := []int{1,2,3} |
DP
有最优子结构的问题:
可以【自顶向下】,使用递归来做。拆分问题。其中递归的过程里可以使用【记忆化】的技巧,避免多次计算。
更进一步
直接【自底向上】,使用一个结果数组,一步步推导上去。比如求ans[n],我从 ans[0]开始一直求到ans[n],反正你上面递归的方法也是一层层都求过一遍的。
排序
go 倒序
1 | sort.Sort(sort.Reverse(sort.IntSlice(coins))) |
Adopting CC BY-NC-SA 4.0 License Agreement




