funcmakemap(t *maptype, hint int, h *hmap) *hmap { hint 为 map 拟分配的容量;在分配前,会提前对拟分配的内存大小进行判断,倘若超限,会将 hint 置为零; mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) if overflow || mem > maxAlloc { hint = 0 }
if h == nil { h = new(hmap) } h.hash0 = fastrand() 调用 fastrand,构造 hash 因子:hmap.hash0;
B := uint8(0) for overLoadFactor(hint, B) { 大致上基于 log2(B) >= hint 的思路计算桶数组的容量 B;overLoadFactor具体内容下面马上贴 B++ } h.B = B
// 通过 hash&m 可以知道桶的位置b。其实就是取余运算。 x % 4 => x & 3 (4是 100, 3 是 011) b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil { // 在取老桶前,会先判断 map 的扩容流程是否是增量扩容,倘若是的话,说明老桶数组的长度是新桶数组的一半,需要将桶长度值 m 除以 2. if !h.sameSizeGrow() { m >>= 1// 除以 2 } // 如果是在渐进式 hash,则要看看是不是找老 b oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) if !evacuated(oldb) { // evacuated 会告诉你有没有迁移完 b = oldb // 没迁移完,就从老 b 里找 } }
top := tophash(hash) //取出高 8 位. tophash具体下面会贴 bucketloop: for ; b != nil; b = b.overflow(t) { // 外层for基于桶链表 依次遍历首个桶和后续的每个溢出桶 for i := uintptr(0); i < bucketCnt; i++ { // 内层依次遍历一个桶内的 key-value 对. if b.tophash[i] != top { // 高 8 位不等于 tophash 值,可以跳过,但 go 还做了一个 tophash 判断是否删除的设计。 if b.tophash[i] == emptyRest { // 倘若不匹配且当前位置 tophash 值为 0,说明桶的后续位置都未放入过元素,当前 key 在 map 中不存在,可以直接打破循环,返回零值. 这就是上面提到的 tophash 特殊标识的用法 break bucketloop } continue } // 高 8 位相等。进一步比较 key 是不是一致 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { // 倘若找到了相等的 key,则通过地址偏移的方式取到 value e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))// 其中 dataOffset 为一个桶中 tophash 数组所占用的空间大小. 这个数字每次都是固定的。就是 x*8 if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } return e //返回 } } } // 找不到,反 0 值 return unsafe.Pointer(&zeroVal[0]) }
// 从 map 的桶数组 buckets 出发,结合桶索引和桶容量大小,进行地址偏移,获得对应桶 b; b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) top := tophash(hash) //取得 key 的高 8 位 tophash:
var inserti *uint8//tophash 拟插入位置 var insertk unsafe.Pointer //key 拟插入位置 var elem unsafe.Pointer //val 拟插入位置 bucketloop: // 2 层循环找位置入桶 for { // 这层 for 的终止条件是内层的后面的 if ovf == nil for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if isEmpty(b.tophash[i]) && inserti == nil { // isEmpty下面会贴。就是判断是不是<=1 // <=1 说明已经找不到了。可以 break
bucket := hash & bucketMask(h.B) //找到当前 key 对应的桶索引 bucket; if h.growing() { // 倘若发现当前 map 正处于扩容过程,则帮助其渐进扩容 growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) // 从 map 的桶数组 buckets 出发,结合桶索引和桶容量大小,进行地址偏移,获得对应桶 b,并赋值给 bOrg bOrig := b top := tophash(hash) //取得 key 的高 8 位 tophash search: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { // 后头都没啥了。别找了 break search } continue }
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))// 地址偏移获得现在的 k k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } if !t.key.equal(key, k2) { // 不相等,则继续遍历 continue }
// 则删除对应的 key-value 对 // Only clear key if there are pointers in it. if t.indirectkey() { *(*unsafe.Pointer)(k) = nil } elseif t.key.ptrdata != 0 { memclrHasPointers(k, t.key.size) } e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { *(*unsafe.Pointer)(e) = nil } elseif t.elem.ptrdata != 0 { memclrHasPointers(e, t.elem.size) } else { memclrNoHeapPointers(e, t.elem.size) } b.tophash[i] = emptyOne //将当前位置的 tophash 置为 emptyOne if i == bucketCnt-1 { if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest { goto notLast } } else { if b.tophash[i+1] != emptyRest { // 倘若当前位置不位于最后一个桶的最后一个位置,或者当前位置的后置位 tophash 不为 emptyRest,则无需向前遍历更新 tophash 标识,直接跳转到 notLast 位置即可; goto notLast } } for { // 向前遍历,将沿途的空位( tophash 为 emptyOne )的 tophash 都更新为 emptySet. b.tophash[i] = emptyRest if i == 0 { // 更新到头了。往前找一个桶 if b == bOrig { // 前面也不会有桶了 break } c := b for b = bOrig; b.overflow(t) != c; b = b.overflow(t) { } // 定位到当前的桶 i = bucketCnt - 1//调整下标,从最后一个开始搞! } else { i-- } if b.tophash[i] != emptyOne { break//不是空才停止 } } notLast: // 倘若成功从 map 中删除了一组 key-value 对,则将 hmap 的计数器 count 值减 1. h.count-- if h.count == 0 { // 倘若 map 中的元素全都被删除完了,会为 map 更换一个新的随机因子 hash0. h.hash0 = fastrand() } break search } }
// decide where to start // 通过取随机数的方式,决定遍历时的起始桶,以及桶中起始 key-value 对的位置。一定注意。有两个随机。 var r uintptr r = uintptr(fastrand()) it.startBucket = r & bucketMask(h.B) // startBucket 是随机的。(开始的桶位置 it.offset = uint8(r >> h.B & (bucketCnt - 1)) // offset 也是随机的。(每个桶开始的元素位置
// iterator state it.bucket = it.startBucket
// Remember we have an iterator. // Can run concurrently with another mapiterinit(). if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator { atomic.Or8(&h.flags, iterator|oldIterator) }
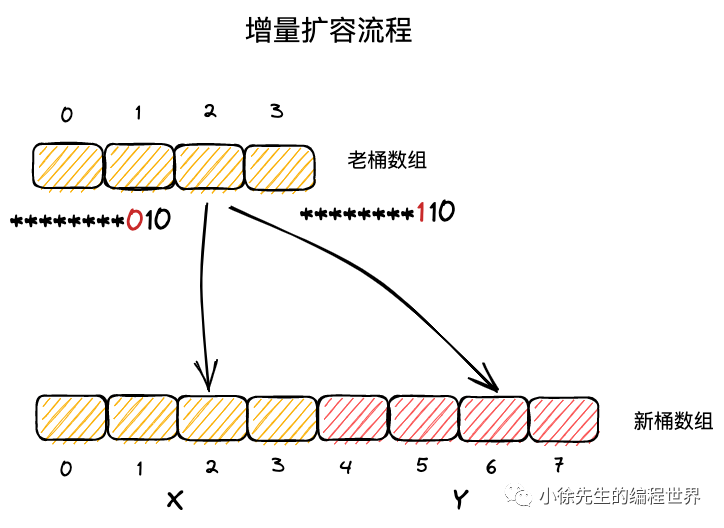
(6)在增量扩容流程中,新桶数组的长度会扩展一位,假定 key 原本从属的桶号为 i,则在新桶数组中从属的桶号只可能是 i (x 区域)或者 i + 老桶数组长度(y 区域);
(7)当 key 低位 hash 值向左扩展一位的 bit 位为 0,则应该迁往 x 区域的 i 位置;倘若该 bit 位为 1,应该迁往 y 区域对应的 i + 老桶数组长度的位置.
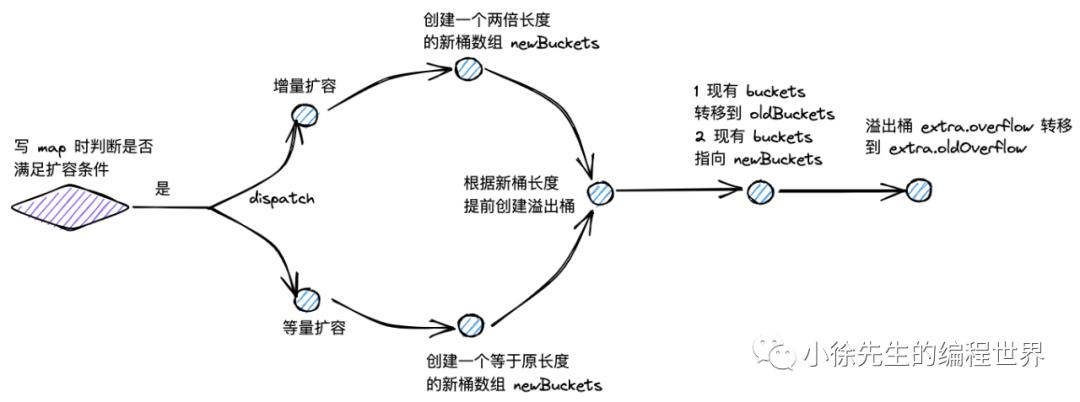
9.5 渐进式扩容
map 采用的是渐进扩容的方式,避免因为一次性的全量数据迁移引发性能抖动.
当每次触发写、删操作时,会为处于扩容流程中的 map 完成两组桶的数据迁移:
(1)一组桶是当前写、删操作所命中的桶;
(2)另一组桶是,当前未迁移的桶中,索引最小的那个桶.
1 2 3 4 5 6 7 8 9 10 11
func growWork(t *maptype, h *hmap, bucket uintptr) { // make sure we evacuate the oldbucket corresponding // to the bucket we're about to use evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing if h.growing() { evacuate(t, h, h.nevacuate) } }
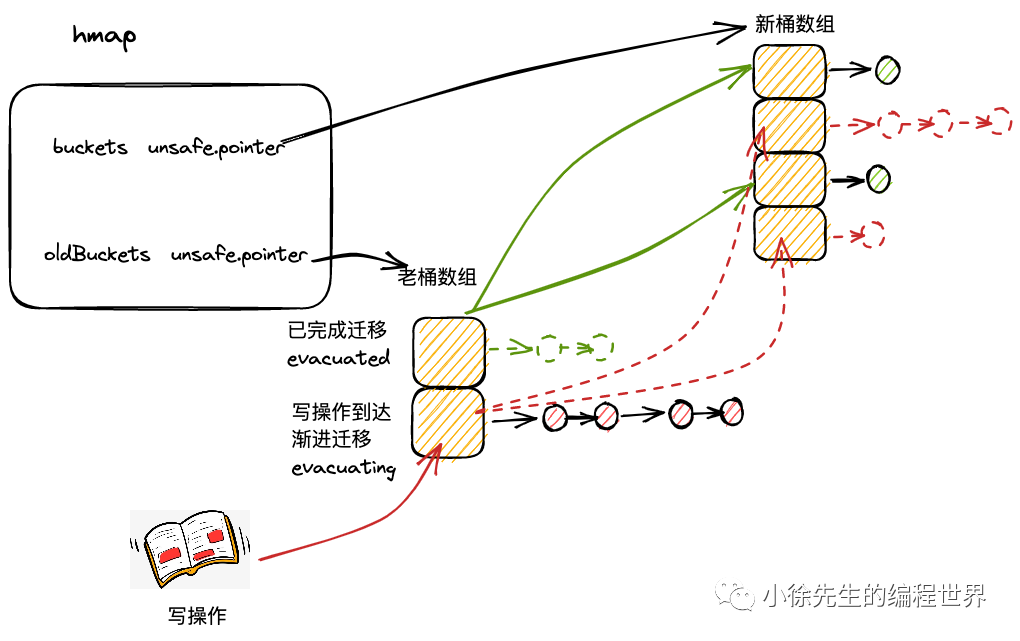
func evacuate(t *maptype, h *hmap, oldbucket uintptr) { // 入参中,oldbucket 为当前要迁移的桶在旧桶数组中的索引 // 获取到待迁移桶的内存地址 b b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) // 获取到旧桶数组的容量 newbit newbit := h.noldbuckets() // evacuated 方法判断出桶 b 是否已经迁移过了,未迁移过,才进入此 if 分支进行迁移处理 if !evacuated(b) { // 通过一个二元数组 xy 指向当前桶可能迁移到的目的桶 // x = xy[0],代表新桶数组中索引和旧桶数组一致的桶 // y = xy[1],代表新桶数组中,索引为原索引加上旧桶容量的桶,只在增量扩容中会使用到 var xy [2]evacDst x := &xy[0] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 只有进入增量扩容的分支,才需要对 y 进行初始化 if !h.sameSizeGrow() { // Only calculate y pointers if we're growing bigger. // Otherwise GC can see bad pointers. y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr(t.keysize)) }
// 外层 for 循环,遍历桶 b 和对应的溢出桶 for ; b != nil; b = b.overflow(t) { // k,e 分别记录遍历桶时,当前的 key 和 value 的指针 k := add(unsafe.Pointer(b), dataOffset) e := add(k, bucketCnt*uintptr(t.keysize)) // 遍历桶内的 key-value 对 for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) { top := b.tophash[i] if isEmpty(top) { b.tophash[i] = evacuatedEmpty continue } if top < minTopHash { throw("bad map state") } k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 if !h.sameSizeGrow() { // Compute hash to make our evacuation decision (whether we need // to send this key/elem to bucket x or bucket y). hash := t.hasher(k2, uintptr(h.hash0)) if hash&newbit != 0 { useY = 1 } } b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY dst := &xy[useY] // evacuation destination if dst.i == bucketCnt { dst.b = h.newoverflow(t, dst.b) dst.i = 0 dst.k = add(unsafe.Pointer(dst.b), dataOffset) dst.e = add(dst.k, bucketCnt*uintptr(t.keysize)) } dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check if t.indirectkey() { *(*unsafe.Pointer)(dst.k) = k2 // copy pointer } else { typedmemmove(t.key, dst.k, k) // copy elem } if t.indirectelem() { *(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e) } else { typedmemmove(t.elem, dst.e, e) } dst.i++ dst.k = add(dst.k, uintptr(t.keysize)) dst.e = add(dst.e, uintptr(t.elemsize)) } } // Unlink the overflow buckets & clear key/elem to help GC. if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 { b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)) // Preserve b.tophash because the evacuation // state is maintained there. ptr := add(b, dataOffset) n := uintptr(t.bucketsize) - dataOffset memclrHasPointers(ptr, n) } }
if oldbucket == h.nevacuate { advanceEvacuationMark(h, t, newbit) } }
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
(2)获取到老桶数组的长度 newbit;
1
newbit := h.noldbuckets()
(3)倘若当前桶已经完成了迁移,则无需处理;
(4)创建一个二元数组 xy,分别承载 x 区域和 y 区域(含义定义见 9.4 小节)中的新桶位置,用于接受来自老桶数组的迁移数组;只有在增量扩容的流程中,才存在 y 区域,因此才需要对 xy 中的 y 进行定义;
1 2 3 4 5 6 7 8 9 10 11 12 13
var xy [2]evacDst x := &xy[0] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() { y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr(t.keysize)) }
(5)开启两层 for 循环,外层遍历桶链表,内层遍历每个桶中的 key-value 对:
1 2 3 4 5 6 7 8
for ; b != nil; b = b.overflow(t) { k := add(unsafe.Pointer(b), dataOffset) e := add(k, bucketCnt*uintptr(t.keysize)) for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) { // ... } }
top := b.tophash[i] if isEmpty(top) { b.tophash[i] = evacuatedEmpty continue }
(7)基于 9.4 的规则,寻找到迁移的目的桶;
1 2 3 4 5 6 7 8 9 10 11 12 13 14
const evacuatedX = 2 const evacuatedY = 3
k2 := k var useY uint8 if !h.sameSizeGrow() { hash := t.hasher(k2, uintptr(h.hash0)) if hash&newbit != 0 { useY = 1 } } b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY dst := &xy[useY]
其中目的桶的类型定义如下:
1 2 3 4 5 6
type evacDst struct { b *bmap // current destination bucket i int // key/elem index into b k unsafe.Pointer // pointer to current key storage e unsafe.Pointer // pointer to current elem storage }


...)

